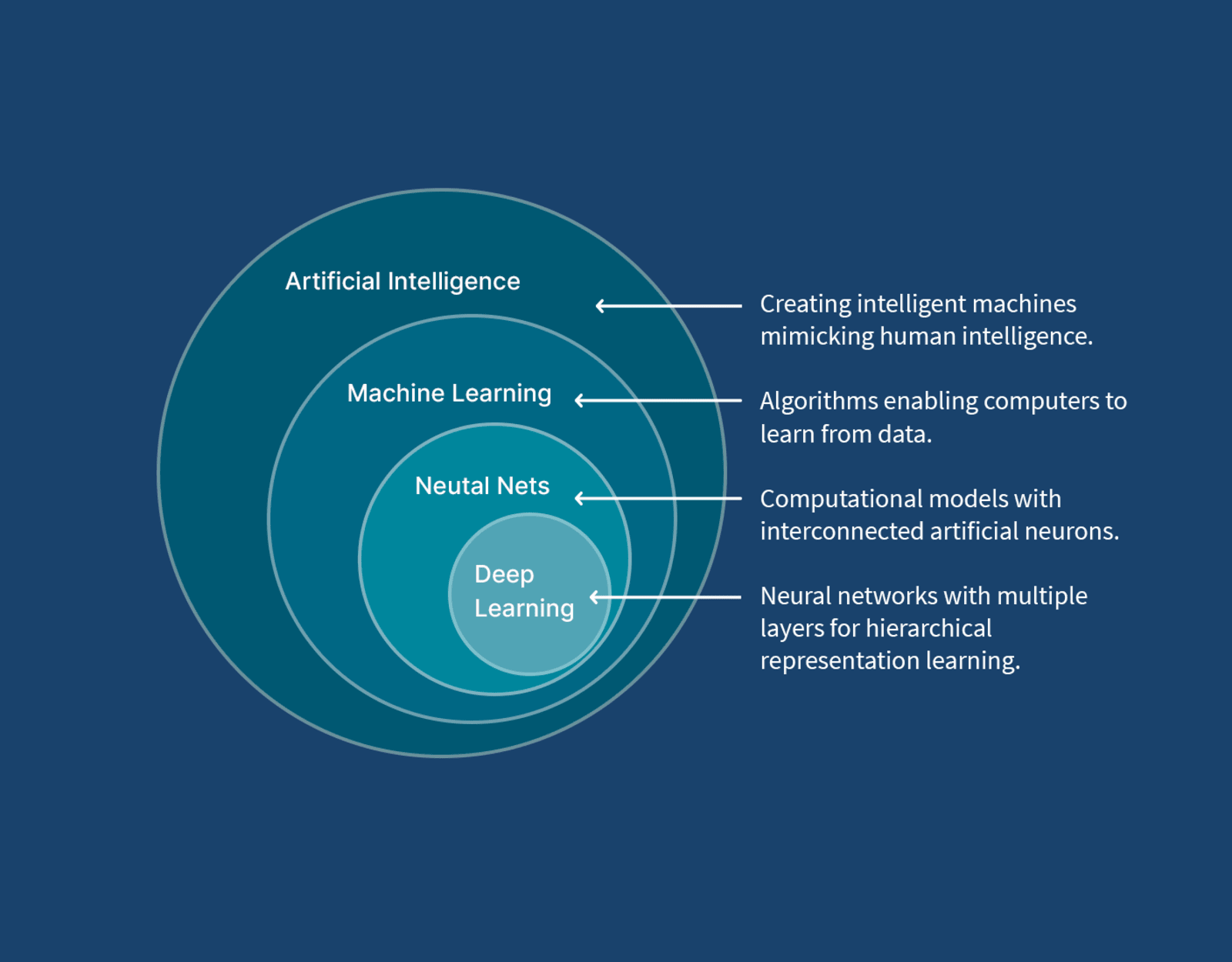
Artificial intelligence
- AI allows a machine to simulate human intelligence to solve problems
- The goal is to develop an intelligent system that can perform complex tasks
- We build systems that can solve complex tasks like a human
- AI has a wide scope of applications
- AI uses technologies in a system so that it mimics human decision-making
- AI works with all types of data: structured, semi-structured, and unstructured
- AI systems use logic and decision trees to learn, reason, and self-correct
Machine learning
- ML allows a machine to learn autonomously from past data
- The goal is to build machines that can learn from data to increase the accuracy of the output
- We train machines with data to perform specific tasks and deliver accurate results
- Machine learning has a limited scope of applications
- ML uses self-learning algorithms to produce predictive models
- ML can only use structured and semi-structured data
- ML systems rely on statistical models to learn and can self-correct when provided with new data
Differences between AI and ML
While artificial intelligence encompasses the idea of a machine that can mimic human intelligence, machine learning does not. Machine learning aims to teach a machine how to perform a specific task and provide accurate results by identifying patterns.
Drawing 2025-11-05 10.59.46
Link to original
Data privacy and security are especially critical within the banking industry. Financial services leaders can keep customer data secure while increasing efficiencies using AI and machine learning in several ways:
- Using machine learning to detect and prevent fraud and cybersecurity attacks
- Integrating biometrics and computer vision to quickly authenticate user identities and process documents
- Incorporating smart technologies such as chatbots and voice assistants to automate basic customer service functions
How machine learning transforms cybersecurity
The ability of machine learning models to process and draw inferences from vast amounts of data is the driving force behind the cybersecurity transformations. Traditional security tools primarily rely on predefined rules and known threat signatures, which limits their ability to detect novel or evolving attacks.
Machine learning is reshaping cybersecurity strategies by enabling adaptive, proactive defenses. As threats evolve, so do the models trained to combat them, allowing organizations to shift from reactive to predictive security postures.
Machine learning models continuously learn from vast volumes of data to identify patterns and anomalies in real time. These insights allow organizations to identify new threats, including zero-day attacks, before they can cause significant harm.
In addition to detection, machine learning drives automation in incident response and management. Machine learning in cybersecurity systems can initiate predefined actions (e.g., isolating affected systems or blocking malicious internet protocol (IP) addresses) within seconds of detecting a threat. This minimizes the potential damage and helps organizations maintain continuity during an attack. It also helps security teams to prioritize alerts more effectively and reduce the time it takes to investigate and contain threats.
What is the role of AI and Machine Learning in cybersecurity?
Artificial intelligence (AI) and machine learning have become core components of cybersecurity solutions due to their ability to predict, detect, and respond to threats with unprecedented accuracy and speed. Key functions of AI and machine learning in cybersecurity include:
- Analyzing patterns and detecting anomalies that may indicate a security breach or an impending attack
- Automating complex security processes and incident responses
- Bolstering the efficacy of existing cybersecurity measures
- Continuously learning from historical and real-time data
- Detecting unknown malware and zero-day attacks
- Enabling adaptive defense mechanisms that evolve based on previous encounters with cyber threats
- Forecasting potential vulnerabilities
- Optimizing security policies based on real-world behavior
- Reducing reliance on manual interventions
- Simulating attack scenarios
how-ai-and-machine-learning-are-improving-cybersecurity
Introduction
Artificial Intelligence (AI) is the term used to describe systems that mimic human intelligence in order to solve problems, make decisions, and adjust to new information in a variety of tasks. Machine Learning (ML), a subfield of this larger field, is more specifically concerned with empowering machines to learn on their own from historical data. This is achieved through the use of statistical models and self-learning algorithms to create predictive models that gradually increase in accuracy. While AI can replicate human decision-making using structured, semi-structured, and unstructured data, machine learning (ML) usually uses structured and semi-structured data to find patterns and improve performance on particular tasks. Because of these qualities, AI and ML are especially crucial in data-sensitive industries like banking and cybersecurity, where speed, dependability, and privacy are essential. Conventional security tools mainly depend on preset. Because of these qualities, AI and ML are especially crucial in data-sensitive industries like banking and cybersecurity, where speed, dependability, and privacy are essential. The capacity of traditional security tools to identify new or quickly changing attacks is constrained by their heavy reliance on predefined rules and known threat signatures. On the other hand, machine learning models are able to analyze enormous amounts of activity data in real time, identify irregularities, and assist in identifying threats that were previously unknown, such as zero-day attacks, before they have a significant negative impact. At the same time, routine security and customer service tasks are automated by AI-driven technologies like biometric authentication, computer vision-based document processing, and conversational agents like chatbots and voice assistants. In this sense, artificial intelligence (AI) and machine learning (ML) are changing cybersecurity from a primarily reactive, rule-based procedure to an adaptive, predictive system that continuously learns, self-corrects, and improves an organization’s overall security posture.
Scribbr
To what extent can Machine Learning-based anomaly detection reduce false positives in cybersecurity threat detection compared to traditional rule-based methods?
Cybersecurity systems are constantly scanning for threats, but they often raise alarms for activities that turn out to be harmless. These incorrect alerts, known as false positives, can overwhelm security teams and lead to wasted effort. This paper investigates how machine learning-based anomaly detection can help reduce false positives compared to traditional rule-based threat detection methods.
This paper begins by outlining the issue of false positives and its significance. The operation of conventional rule-based detection is then explained, along with some of its advantages and disadvantages (such as low false positives for known threats but trouble adjusting to new attacks). The study then presents machine learning anomaly detection, showing how it can identify unusual patterns and possibly eliminate a large number of false alarms by learning typical behavior. To illustrate the distinctions, we draw on real-world case studies and applicable examples from credible cybersecurity literature. We describe, for example, how an intelligent AI system might identify normal behavior as benign, while a static rule might mistakenly flag it as malicious.
The assertion that machine learning techniques, when appropriately implemented, can dramatically lower the quantity of false positive alerts is backed up by data from industry reports and published research. But we also talk about the difficulties: in order to prevent their own errors, machine learning models need high-quality data and tuning. The study concludes that although machine learning-based anomaly detection is not flawless, it presents a viable route toward threat detection that is more accurate and produces a significantly lower number of false alarms than conventional techniques. For strong cybersecurity, a combined strategy that makes use of both rules and machine learning seems to work best. This thorough review prioritizes concrete examples over intricate theory and offers high-level insights appropriate for a broad audience.
Main
Cybersecurity systems are constantly scanning for threats, but they often raise alarms for activities that turn out to be harmless. These incorrect alerts, known as false positives, can overwhelm security teams and lead to wasted effort. This paper investigates how machine learning-based anomaly detection can help reduce false positives compared to traditional rule-based threat detection methods.
Every alert typically requires investigation by security analysts. When most alerts are false positives, analysts spend countless hours checking on non-issues instead of hunting real threats. Industry studies estimate that organizations collectively waste millions of dollars and tens of thousands of work-hours per year chasing false alerts (Wiens, 2022). On average, enterprises spend over 21,000 hours (and over $1.3 million in labor costs) annually investigating alerts that turn out to be false alarms (Wiens, 2022). This is time and money that could have been directed toward strengthening defenses or responding to actual incidents.
A flood of false alarms can overwhelm security teams, a phenomenon often called “alert fatigue.” When analysts are inundated with thousands of alerts each day – many of them false – it becomes difficult to distinguish the real threats from the noise. People may start to ignore or dismiss alerts because they assume they are probably false. This is extremely dangerous because it means a real attack could slip through unnoticed. As one expert review notes, too many false positives can cause analysts to tune out alerts, potentially missing genuine cyberattacks (Mohamed, 2025). In other words, an important alarm might be lost in a sea of irrelevant notifications.
Additionally, false positives may interfere with regular business operations. For example, a security tool may quarantine or remove a crucial system file or update if it incorrectly classifies it as malicious (a situation that has occurred in the past). For instance, a core Windows file (svchost.exe) was mistakenly identified as a virus by an antivirus program in 2010 and subsequently deleted, resulting in numerous computer crashes (Sadoian, 2025). These instances show that false positives are more than just hypothetical irritations; they can result in actual, detrimental outcomes like system outages or blocked services because of an incorrect alert.
Rule-based
Traditional cybersecurity threat detection relies heavily on rule-based or signature-based approaches. In a rule-based system, human experts write specific rules or patterns that indicate malicious behavior. These rules can be as simple as “block any login attempt outside of business hours” or as complex as a pattern of bytes that signifies a known virus. A classic example is antivirus software, which uses a database of malware signatures (unique patterns of code or behavior for each known virus) to scan files and processes. If a file matches a known bad signature, it’s flagged or blocked immediately.
Rule-based systems operate on an If-Then logic. If an event or data matches a predefined pattern (the rule), then trigger an alert or action. For instance, a firewall might have a rule to drop network traffic coming from an IP address that has been identified as malicious, or an intrusion detection system might alert if it sees a series of failed login attempts exceeding a certain number (since that might indicate a brute-force attack). These rules are often derived from past incidents and expert knowledge; they excel at catching threats that are already known and well-defined (Yahya, 2025).
Benefits
Rules are usually easy to understand and explain. Each rule has a specific rationale. For example, a rule might say “if any program tries to modify system files in a certain way, alert the admin.” Because of this simplicity, the outcomes are predictable – the system will behave exactly as programmed, which gives a level of transparency (Tencent Cloud, 2025). Security teams can often fine-tune these rules and immediately see the effect.
A carefully crafted rule can be very precise for the scenario it covers. For known threats, signature-based detection can be extremely accurate – it will almost never flag something that isn’t a match to a known bad pattern (Ravindran et al., 2025).
Because rule-based systems are checking for specific patterns, they can be computationally efficient. A known signature can be searched like a fingerprint, allowing near real-time detection. This is why antivirus scans and network filters can operate quickly even on large amounts of data – the rules give them a clear yes/no test for each scanned item. If a new threat is discovered, security teams can often create a new rule or signature and deploy it quickly across systems.
Weaknesses
Rule-based systems are inherently reactive. They only detect what they have been explicitly programmed to detect. If an attacker comes up with a novel technique or a new piece of malware that doesn’t match any existing rule, the system will likely miss it. In cybersecurity, these unknown attacks are called zero-day threats (meaning no prior signature exists) or simply new variants of malware. Rule-based tools struggle with such scenarios because they cannot generalize beyond their rules. They are essentially “blind” to anything not on their list. This rigidity means attackers who slightly modify their tactics can sometimes evade detection entirely (Tencent Cloud, 2025).
Managing a large set of rules can become very complex. Large organizations might have thousands of different detection rules in their security systems. Each rule might need updating as systems change or as attackers find ways around them. If rules are not maintained (updated or pruned), they can become obsolete or, worse, conflict with each other.
Although well-tuned rules for known threats tend to be precise, problems arise when rules are too broad or misconfigured. Static rules have no context beyond their pattern – they can’t “understand” the situation. For example, imagine a rule that flags any outgoing database connection as suspicious because, in that organization, normally, databases don’t initiate outbound connections. That rule might be valid most of the time.
Rule-based detection is often described as looking for yesterday’s attacks. It works well once you know the pattern of an attack, but it’s not good at detecting something truly new. Attackers can exploit this by designing malware or techniques specifically to avoid existing signatures.
ML-based
Machine learning-based anomaly detection represents a fundamentally different approach to threat detection. Instead of relying on human-defined rules and known signatures, anomaly detection systems use algorithms to learn what normal behavior looks like within a system or network, and then flag anything that deviates significantly from that pattern.
Advantages
The biggest advantage of anomaly detection is the ability to identify novel attacks. Because it isn’t limited to a list of known bad signatures, an anomaly-based IDS can, for example, catch a completely new type of malware communication because it observes that “this process has never sent data to an external server before, and now it is sending a large amount of encrypted data – that’s weird.” Traditional systems would have missed that if the malware was new. Anomaly detection is inherently more proactive; it’s looking for strange behavior in general, which provides a layer of security against the kinds of threats that arise constantly in the cyber world (Mohamed, 2025).
It might seem counterintuitive (given that anomaly systems can also false alarm), but a well-designed ML system can actually reduce false positives by adapting to the environment over time (Hariharasubramanian, 2025). Early on, an anomaly detector might flag several things as it learns. But these systems can incorporate feedback – if certain anomalies are investigated and found harmless, the system can learn from that feedback and adjust its model. Over time, the continuous learning process helps the system better distinguish normal-versus-abnormal, minimizing incorrect alerts (Hariharasubramanian, 2025).
Disadvantages
When first introduced, an anomaly detection system may alert a lot simply because it hasn’t seen enough data to know what’s normal. This “learning phase” can be noisy. Without sufficient training data or time, the system might classify normal fluctuations as anomalies.
References
Yahya, F. (2025). Rule-based access control: A comprehensive guide. Retrieved November 11, 2025, from https://faisalyahya.com/access-control/rule-based-access-control-a-comprehensive-guide/
Hariharasubramanian, N. (2025, January 16). What is anomaly based detection system. Fidelis Security. https://fidelissecurity.com/cybersecurity-101/learn/anomaly-based-detection-system/
Kumar, A., & Gutierrez, J. A. (2025). Impact of machine learning on intrusion detection systems for the protection of critical infrastructure. Information, 16(7), 515. https://doi.org/10.3390/info16070515
Mohamed, N. (2025). Artificial intelligence and machine learning in cybersecurity: a deep dive into state-of-the-art techniques and future paradigms. Knowledge and Information Systems, 67, 6969–7055. https://doi.org/10.1007/s10115-025-02429-y
Ravindran, V. K., Ojha, S. S., & Kamboj, A. (2025). A comparative analysis of signature-based and anomaly-based intrusion detection systems. International Journal of Latest Technology in Engineering, Management & Applied Science, 14(5), 209–214. https://doi.org/10.51583/IJLTEMAS.2025.140500026
Sadoian, L. (2025, March 19). The cost of false positives: Why cybersecurity accuracy matters. UpGuard. https://www.upguard.com/blog/false-positives
Wiens, C. (2022, February 24). Better anomaly detection is key to solving the false positive problem once and for all. MixMode. https://www.mixmode.ai/blog/better-anomaly-detection-is-key-to-solving-the-false-positive-problem-once-and-for-all
Ponemon Institute. (2015). The cost of malware containment. Damballa.
https://www.ponemon.org/local/upload/file/Damballa%20Malware%20Containment%20FINAL%203.pdf